|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
|
"""
Survived Survival status 0 = No, 1 = Yes
PassengerId Problem delivered at test time
Pclass Passenger Class 1 = 1st, 2 = 2nd, 3 = 3rd
Sex
Name
Age
SibSp Number of Siblings/Spouses Aboard
Parch Number of Parents/Children Aboard
Ticket Ticket number
Fare Passenger Fare
Cabin Room number
boat - Lifeboat (if survived)
body - Body number (if did not survive and body was recovered)
Embarked name of port on board C = Cherbourg, Q = Queenstown, S = Southampton
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')
"""
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
class Titanic:
context : str
fname : str
train : object
test : object
id : str
model : object
label : object
@property
def context(self) -> str: return self._context
@context.setter
def context(self, context): self._context = context
@property
def fname(self) -> str: return self._fname
@fname.setter
def fname(self, fname): self._fname = fname
@property
def train(self) -> str: return self._train
@train.setter
def train(self, train): self._train = train
@property
def test(self) -> str: return self._test
@test.setter
def test(self, test): self._test = test
@property
def id(self) -> str: return self._id
@id.setter
def id(self, id): self._id = id
@property
def label(self) -> str: return self._label
@label.setter
def label(self, label): self._label = label
@property
def model(self) -> str: return self._model
@model.setter
def model(self, model): self._model = model
def new_file(self) -> str: return self._context + self._fname
def new_dframe(self) -> object: return pd.read_csv(self.new_file())
def modeling(self,this):
print('1. Drop PassengerId, Cabin, Ticket')
this = self.drop_feature(this, 'PassengerId')
this = self.drop_feature(this, 'Cabin')
this = self.drop_feature(this, 'Ticket')
print('2. Embarked, Sex Nominal')
this = self.embarked_nominal(this)
this = self.sex_nominal(this)
print('3. Fare Ordinal ')
this = self.fare_ordinal(this)
this = self.drop_feature(this, 'Fare')
print('4. Title Nominal ')
this = self.title_nominal(this)
this = self.drop_feature(this, 'Name')
print('5. Age Ordinal ')
this = self.age_ordinal(this)
print('6. Final Null Check')
print('train null count \n {}'.format(this.train.isnull().sum()))
print('test null count \n {}'.format(this.test.isnull().sum()))
self.model = this.train.drop('Survived', axis=1)
self.label = this.train['Survived']
return this
@staticmethod
def age_ordinal(this)-> object:
train = this.train
test = this.test
train['Age'] = train['Age'].fillna(-0.5)
test['Age'] = test['Age'].fillna(-0.5)
bins = [-1, 0, 5, 12, 18, 24, 35, 60, np.inf]
labels = ['Unknown', 'Baby', 'Child', 'Teenager','Student','Young Adult','Adult','Senior']
train['AgeGroup'] = pd.cut(train['Age'], bins, labels=labels)
test['AgeGroup'] = pd.cut(test['Age'], bins, labels=labels)
age_title_mappeing = {
0: 'Unknown', 1: 'Baby', 2: 'Child', 3: 'Teenager', 4: 'Student', 5: 'Young Adult', 6: 'Adult', 7: 'Senior'
}
for x in range(len(train['AgeGroup'])):
if train['AgeGroup'][x] == 'Unknown':
train['AgeGroup'][x] = age_title_mappeing[train['Title'][x]]
for x in range(len(test['AgeGroup'])):
if test['AgeGroup'][x] == 'Unknown':
test['AgeGroup'][x] = age_title_mappeing[test['Title'][x]]
age_mapping = {
'Unknown': 0, 'Baby': 1, 'Child': 2, 'Teenager': 3, 'Student': 4,'Young Adult': 5, 'Adult': 6,'Senior':7
}
this.train['AgeGroup'] = train['AgeGroup'].map(age_mapping)
this.test['AgeGroup'] = test['AgeGroup'].map(age_mapping)
return this
@staticmethod
def title_nominal(this)-> object:
combine = [this.train, this.test]
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z])\.', expand=False)
for dataset in combine:
dataset['Title'] = dataset['Title'].replace(['Capt','Col','Don','Dr','Major','Rev','Jonkheer','Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace(['Countess','Lady','Sir'], 'Royal')
dataset['Title'] = dataset['Title'].replace(['Mile','Ms'], 'Miss')
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Royal": 5, "Rare": 6, "Mne": 7}
for dataset in combine:
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
return this
@staticmethod
def fare_ordinal(this) -> object:
this.train['FareBand'] = pd.qcut(this.train['Fare'], 4, labels=[1,2,3,4])
this.test['FareBand'] = pd.qcut(this.test['Fare'], 4, labels=[1,2,3,4])
this.train = this.train.fillna({'FareBand': 1})
this.test = this.test.fillna({'FareBand': 1})
return this
@staticmethod
def drop_feature(this, feature) -> object:
this.train = this.train.drop([feature], axis= 1)
this.test = this.test.drop([feature], axis= 1)
return this
@staticmethod
def embarked_nominal(this)-> object:
this.train = this.train.fillna({"Embarked" : "S"})
this.test = this.test.fillna({'Embarked': "S"})
city_mapping = {"S": 1, "C": 2, "Q": 3}
this.train['Embarked'] = this.train['Embarked'].map(city_mapping)
this.test['Embarked'] = this.test['Embarked'].map(city_mapping)
return this
@staticmethod
def sex_nominal(this) ->object:
sex_mapping = {"male": 0, "female": 1}
combine = [this.train, this.test]
for dataset in combine:
dataset['Sex'] = dataset['Sex'].map(sex_mapping)
return this
def learning(self, this):
print('Decision Tree Accuracy {} % '.format(self.calculate_accuracy(this, DecisionTreeClassifier())))
print('Random Forest Accuracy {} % '.format(self.calculate_accuracy(this, RandomForestClassifier())))
print('KNN Accuracy {} % '.format(self.calculate_accuracy(this, KNeighborsClassifier())))
print('Naive Bays Accuracy {} % '.format(self.calculate_accuracy(this, GaussianNB())))
print('SVM Accuracy {} % '.format(self.calculate_accuracy(this, SVC())))
@staticmethod
def calculate_accuracy(this, classfier):
score = cross_val_score(classfier,
this.model,
this.label,
cv= KFold(n_splits=10, shuffle= True, random_state=0),
n_jobs=1,
scoring='accuracy')
return round(np.mean(score) * 100, 2)
class View:
@staticmethod
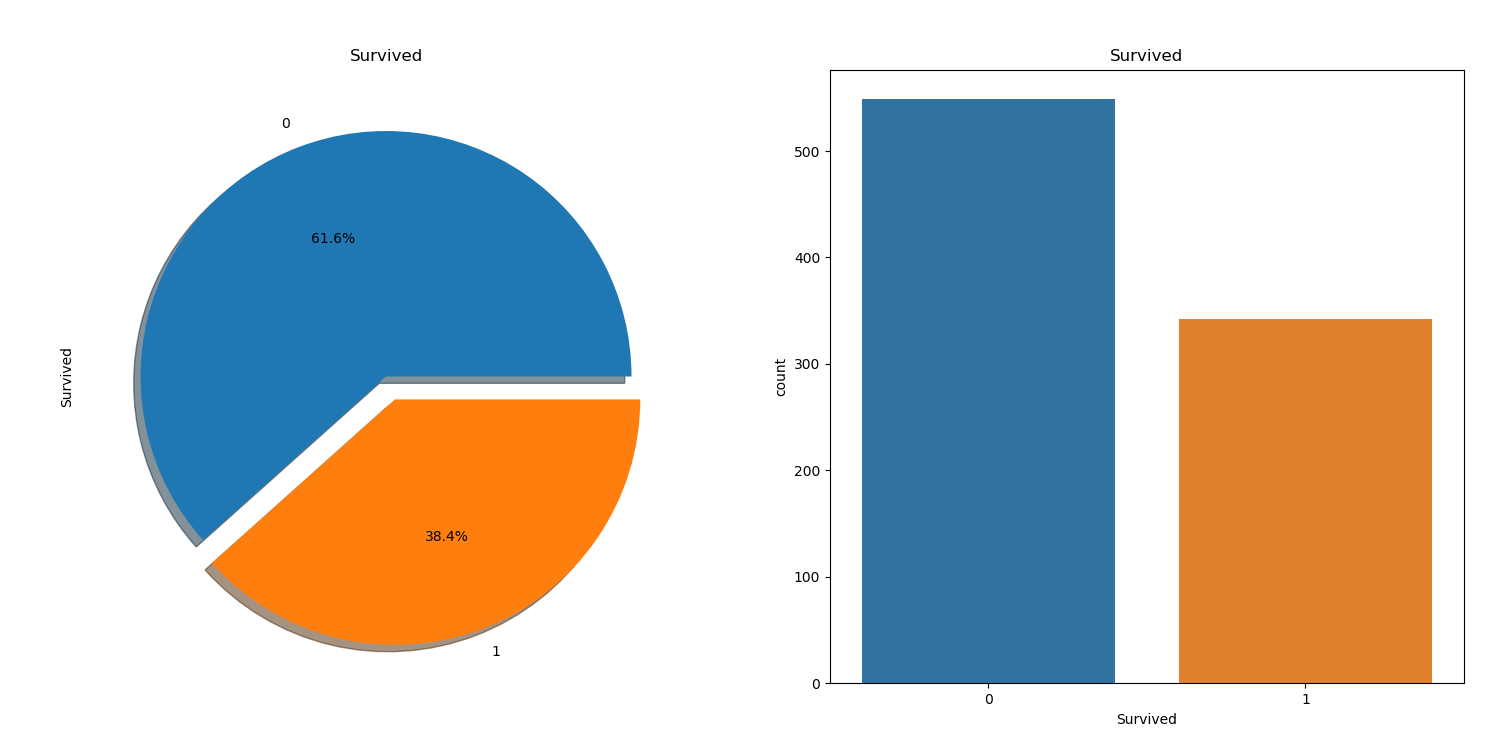
def plot_survived_dead(this):
f, ax = plt.subplots(1, 2, figsize=(18, 8))
this.train['Survived'].value_counts().plot.pie(explode=[0, 0.1],
autopct='%1.1f%%',
ax=ax[0],
shadow=True)
ax[0].set_title('Survived')
ax[1].set_ylabel('')
sns.countplot('Survived', data=this.train, ax=ax[1])
ax[1].set_title('Survived')
plt.show()
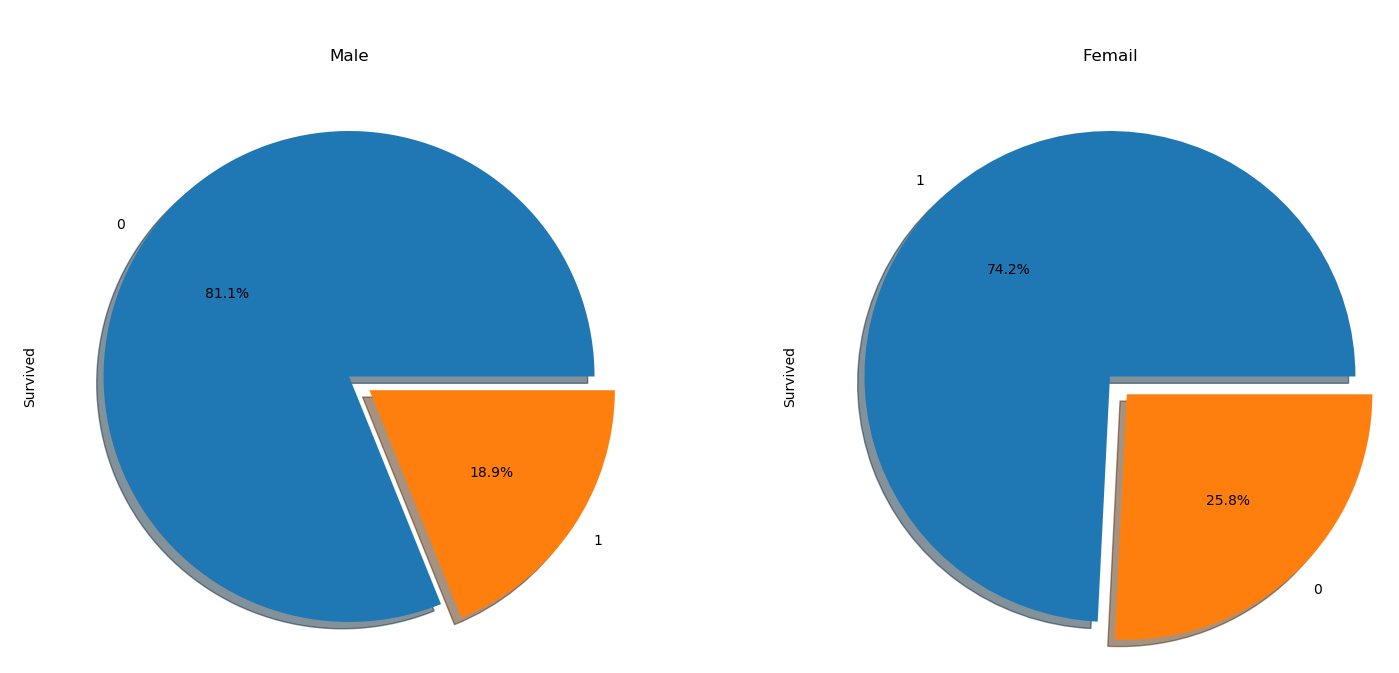
@staticmethod
def plot_sex(this):
f, ax = plt.subplots(1, 2, figsize=(18, 8))
this.train['Survived'][this.train['Sex'] == 'male'].value_counts()\
.plot.pie(explode=[0, 0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
this.train['Survived'][this.train['Sex'] == 'female'].value_counts()\
.plot.pie(explode=[0, 0.1],autopct='%1.1f%%',ax=ax[1],shadow=True)
ax[0].set_title('Male')
ax[1].set_title('Femail')
plt.show()
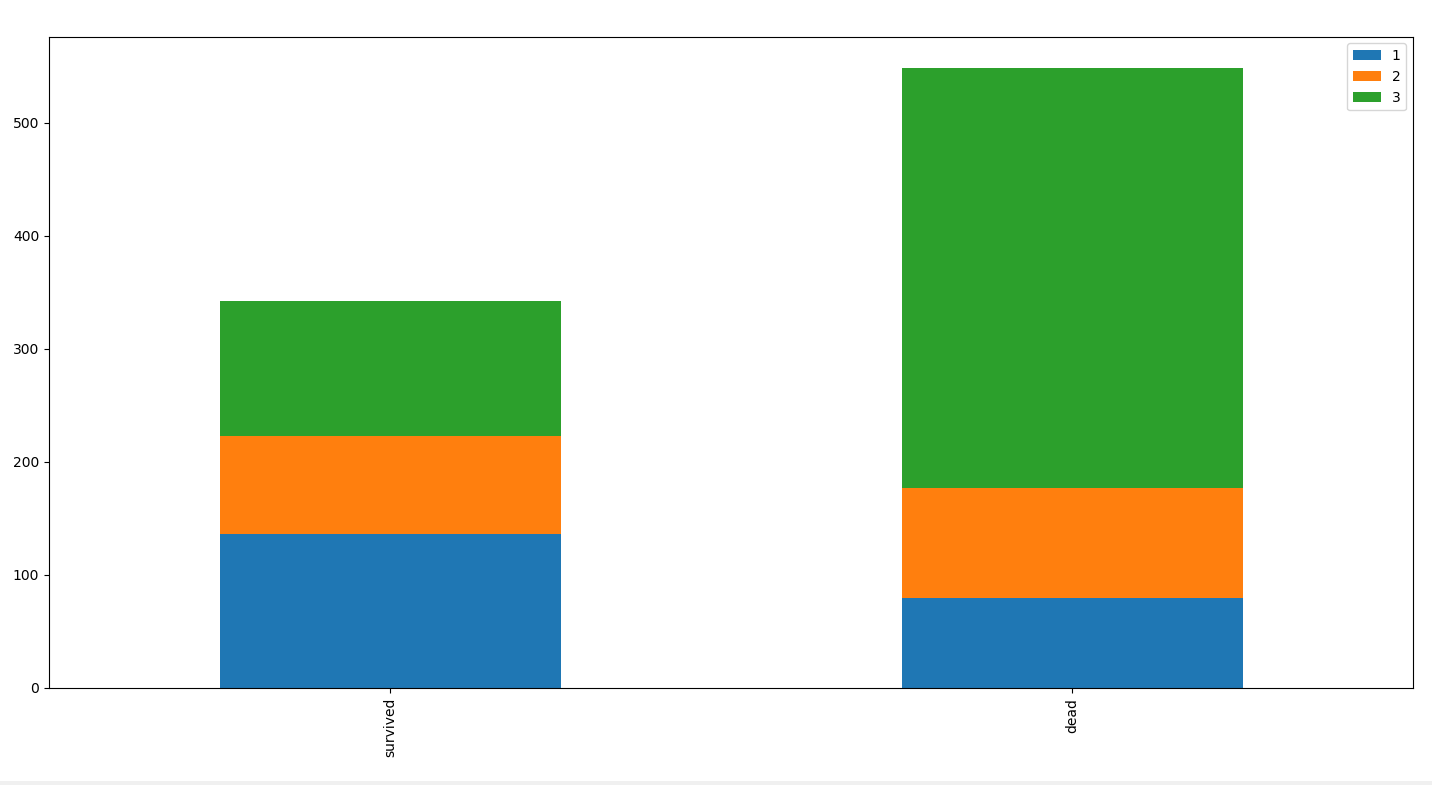
@staticmethod
def bar_chart(this, feature):
survived = this.train[this.train['Survived']==1][feature].value_counts()
dead = this.train[this.train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['survived', 'dead']
df.plot(kind='bar', stacked=True, figsize=(110,1))
plt.show()
if __name__ == '__main__':
def print_menu():
print('0. Exit')
print('1. Create Model')
print('2. Data Visualize')
print('3. Modeling')
print('4. Learning')
print('5. Submit')
return input('Choose One\n')
this = Titanic()
view = View()
while 1:
menu = print_menu()
print(f'Menu : {menu} ')
if menu == '0':
print('Stop')
if menu == '1':
this.context = './data/'
this.fname = 'train.csv'
this.new_file()
this.train = this.new_dframe()
this.fname = 'test.csv'
this.new_file()
this.test = this.new_dframe()
this.id = this.test['PassengerId']
if menu == '2':
view.plot_survived_dead(this)
# view.plot_sex(this)
# view.bar_chart(this, 'Pclass')
if menu == '3':
this = this.modeling(this)
if menu == '4':
this.learning(this)
if menu == '5':
clf = SVC()
clf.fit(this.model, this.label)
prediction = clf.predict(this.test)
submission = pd.DataFrame(
{'PassengerId': this.id, 'Survived': prediction}
)
submission.to_csv('./data/submission.csv', index=False)
|
cs |
'Python' 카테고리의 다른 글
| [플라스크] AI 계산기 ai_calculator.html (0) | 2020.04.30 |
|---|---|
| [플라스크] 계산기 calculator.html (0) | 2020.04.30 |
| [플라스크] login.html (0) | 2020.04.30 |
| [플라스크] index.html (0) | 2020.04.30 |
| [머신러닝] celeb A에서 제공하는 face data 사용하기 (0) | 2020.03.27 |
